Decision Tree and its types
Q: — What is Decision Tree?
A: — It is a set of rules used to classify data into categories. Basically, it’s a greedy divide and conquer algorithm.
It is a non-parametric supervised learning method that can be used for both classification and regression tasks. Decision tree is a hierarchical tree structure that can be used to divide up a large collection of records into smaller sets of classes by applying a sequence of simple decision rules.
We can lay out the possible outcomes and paths. It helps decision-makers to visualize the big picture of the current situation.

Few Terminologies: —
Root Node: — Initial node in tree.
Leaf/Terminal nodes: — Final nodes. Any node whose left and right children are null. Terminal nodes reside in the last level of a binary tree and don’t have any children.
Intermediate or Internal nodes: — Nodes except Root and leaf nodes.
Branch Sub tree: — Subsection of entire tree
Parent/Child Node: — A node which is divided into sub nodes are called parent node whereas sub nodes are called child node.
Pruning: — To reduce size and complexity of a tree by removing sub nodes. In other words, to overcome over fitness.
Types: — ID3, C4.5, C5.0, CART
ID3 (Iterative Dichotomiser 3): — ID3 decision tree algorithm uses Information Gain to decide the splitting points. In order to measure how much information we gain, we can use entropy to calculate the homogeneity of a sample. It uses a top-down greedy approach to build a decision tree.
In simple words, the top-down approach means that we start building the tree from the top and the greedy approach means that at each iteration we select the best feature at the present moment to create a node.
# ID3 only work with Discrete or nominal data.

Entropy: — It is a measure of the amount of uncertainty in a data set. Entropy controls how a Decision Tree decides to split the data. It actually affects how a Decision Tree draws its boundaries.
In simple words, how random our dataset is.

Information Gain: — Information Gain is the decrease or increase in Entropy value when the node is split.

C4.5 and C5.0
C4.5 is the successor to ID3 and C5.0 is the successor to C4.5. Basic difference between C 4.5 and C5.0 is, C5.0 is faster and can be multithreaded, but otherwise generates exactly the same classifiers.
# C4.5 and C5.0 work with both Discrete and Continuous data.
Link: — Is C5.0 Better Than C4.5

CART: — Classification and regression Tree: —
Most popular algorithm in the statistical community. Very similar to C4.5, but it differs in that it supports numerical target variables (regression) and does not compute rule sets. CART uses Gini Impurity.
Gini Impurity is a measure of the purity of the nodes. We compute the probability of the breakage that happens inside the tree.
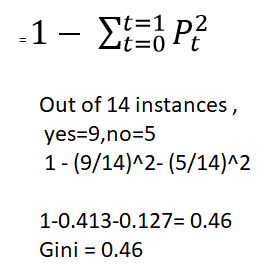
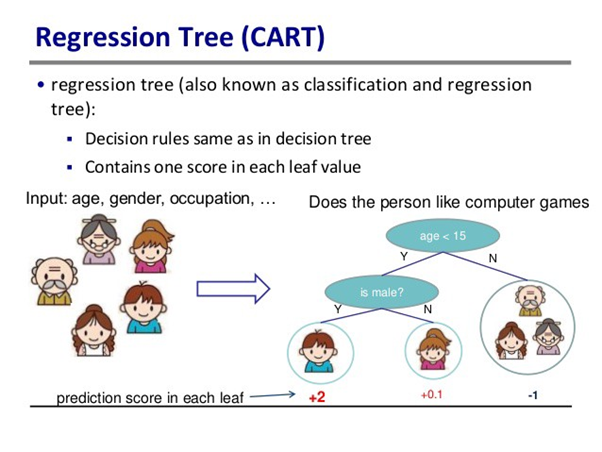
Comparison: —
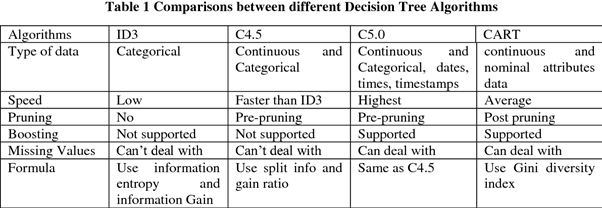
Points to be remember : —
The attribute to be made node is selected using:
· The attribute to be made node is selected using:
· # ID3 only work with Discrete or nominal data.
· C4.5 and C5.0 work with both Discrete and Continuous data
· Information gain in ID3
· Gain ratio in C 4.5
· Gini or any other general function in CART.
Past Blogs : —
Ensemble Techniques in Machine Learning
10 alternatives for Cloud based Jupyter notebook
Statistics — Univariate, Bivariate and Multivariate Analysis
Number System in Python
Thank you for reading this article!!
