Ensemble Techniques in Machine Learning
What do you mean by Ensemble techniques? First lets understand what is Ensemble.
Ensemble : — A group producing a single effect. Ensemble methods are techniques that create multiple models and then combine them to produce improved results.
Ensemble methods can be divided into two groups:
Sequential ensemble methods where the base learners are generated sequentially (e.g. AdaBoost).
Parallel ensemble methods where the base learners are generated in parallel (e.g. Random Forest).
Ensemble methods are meta-algorithms that combine several machine learning techniques into one predictive model in order to Decrease variance, Decrease bias and Improve predictions.

Decrease variance == Bagging
Decrease bias == Boosting
Improve predictions == Stacking


Bagging: — Involves fitting many decision trees on different samples of the same dataset and averaging the predictions. here our goal is to reduce the variance of a decision tree.
Algorithms : — Random forest, Decision tree
#Quick tip : — All learners in Bagging are weak learners. All learners learns from each other independently in parallel and combines them for determining the model average.

Boosting: — involves adding ensemble members sequentially that correct the predictions made by prior models and outputs a weighted average of the predictions.
Algorithms : — XGB, GB, AdaBoost
#Quick tip : — We can create a strong learner from a set of weak learners. In this model, learners learn sequentially and adaptively to improve model predictions of a learning algorithm.

Stacking: — Involves fitting many different models types on the same data and using another model to learn how to best combine the predictions. Algorithms: — Blending, Super Ensemble
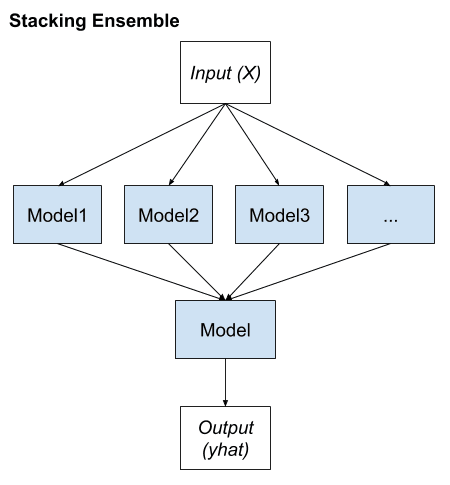
Voting, averaging and Weighted Averaging are basic ensemble methods. They are both easy to understand and implement. Voting is used for classification and averaging is used for regression. In all methods, the first step is to create multiple classification/regression models using some training dataset.
Voting : — Multiple models are used to make predictions for each data point. The predictions by each model are considered as a “vote”. The predictions which we get from the majority of the models are used as the final prediction.
#Terminal nodes in Decision tree, combining them give us the predication. E.g., Which party will win the elections, output will be in binary form (1/0, Yes/No etc.)
Averaging: — Average of predictions from all the models and use it to make the final prediction. Averaging can be used for making predictions in regression problems.
#House price prediction, what will be the house price based on amenities in an area (Not limited to binary form, usually in numbers)
Weighted Average: — An extension of the averaging method. All models are assigned different weights defining the importance of each model for prediction.
#Lets assume you have 10 friends. Two of them are Data Scientists, while others have no prior experience in this field, then the answers by these two friends are given more importance as compared to the other friends.

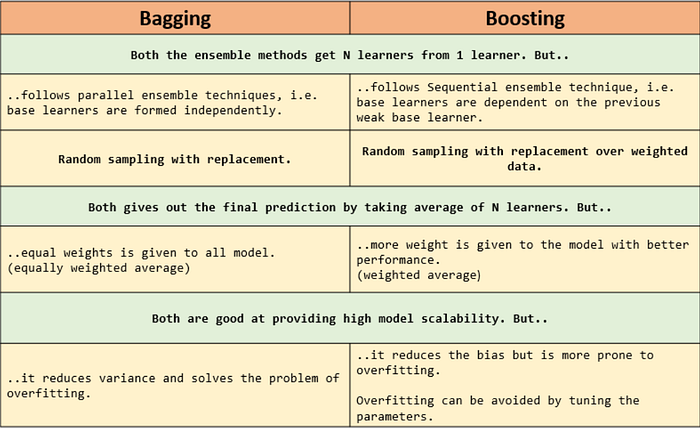
Similarities and difference between Bagging and Boosting: -
Future Blog: — I will share Ensemble Algorithms information and codes in upcoming blogs.
